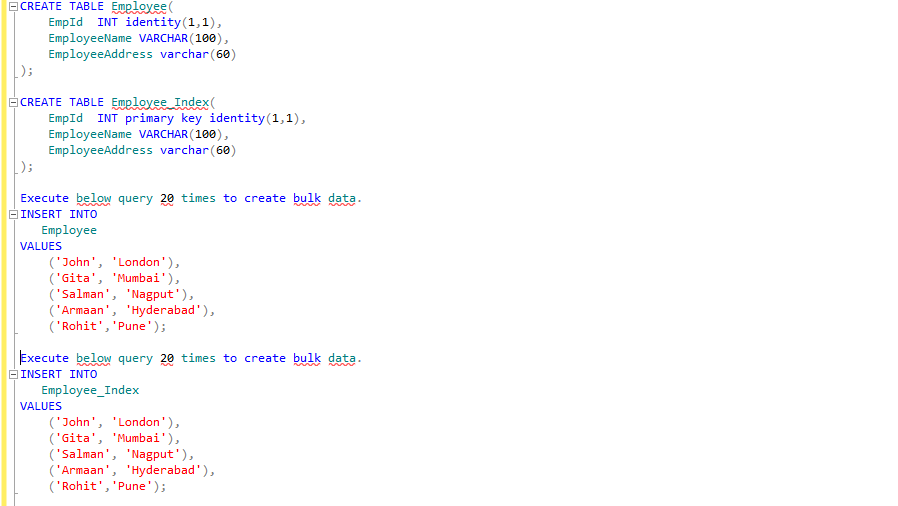
Index in SQL Server
Lets understand disk structure and how table data stores on disk.






posted by Asif Sayyad @ July 21, 2021
0 Comments
![]()
Lets understand disk structure and how table data stores on disk.
posted by Asif Sayyad @ July 21, 2021
0 Comments
![]()
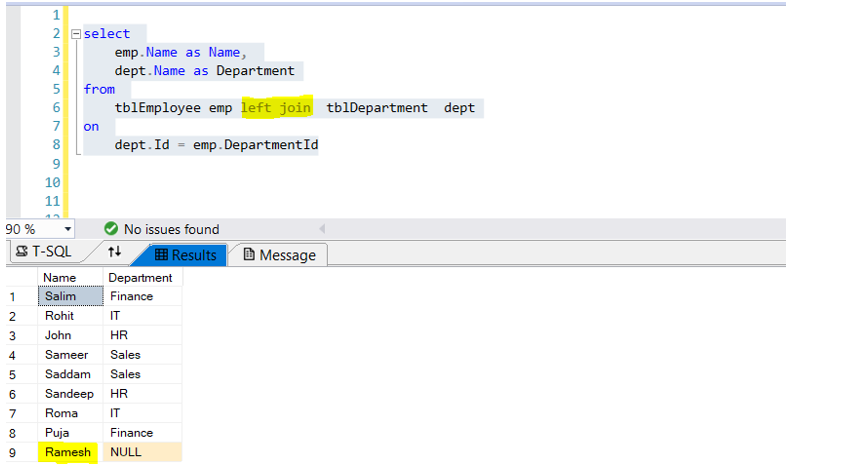
In this article I will explain about joins in SQL server, join means combine/merge tow or more different table in SQL server based on certain join/filter condition. Join applied on two or more table when logical relation exists between SQL server tables. Logical relation means SQL server tables containing Primary and foreign key relation. Join can also be applied on tables which may not be in primary and foreign key relation but data in both tables are more of a like parent-child (primary – foreign key relation). Lets understand with simple example. Types of Join 1. Inner Join 2. Left Join 3. Right Join 4. Full Join 5. Cross Join Before looking into types on join, lets create required tables and insert data. CREATE TABLE [dbo].[tblDepartment] ( [Id] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(50) NULL ) CREATE TABLE [dbo].[tblEmployee] ( [Id] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(50) NULL, [DepartmentId] INT NULL ) I have successfully created tblDepartment and tblEmployee. As discussed, above two tables not following parent-child relationship (primary and foreign key). Let’s insert some dummy data shown below. Insert into tblDepartment values (1, 'IT') Insert into tblDepartment values (2, 'Sales') Insert into tblDepartment values (3, 'HR') Insert into tblDepartment values (4, 'Finance') Insert into tblDepartment (Id, Name) values (5, 'Accounts') Insert into tblEmployee values (1, 'Salim', 4) Insert into tblEmployee values (2, 'Rohit', 1) Insert into tblEmployee values (3, 'John', 3) Insert into tblEmployee values (4, 'Sameer', 2) Insert into tblEmployee values (5, 'Saddam', 2) Insert into tblEmployee values (6, 'Sandeep', 3) Insert into tblEmployee values (7, 'Roma', 1) Insert into tblEmployee values (8, 'Puja', 4) Insert into tblEmployee (Id, Name) values (9, 'Ramesh') Inner Join : It return all the records from both table which satisfy Join condition or common data from both the table based on join condition.








posted by Asif Sayyad @ July 04, 2021
0 Comments
![]()
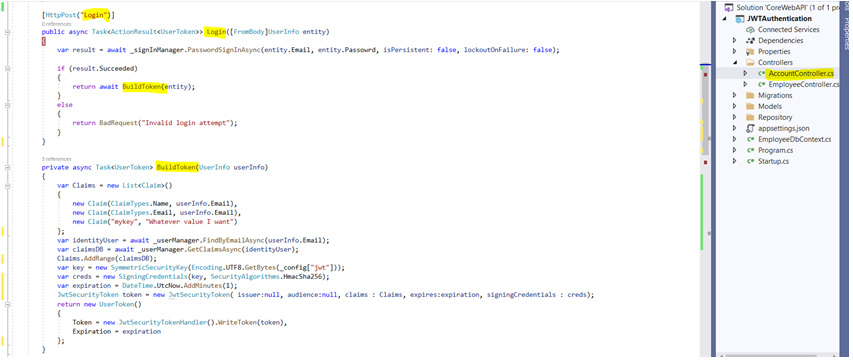
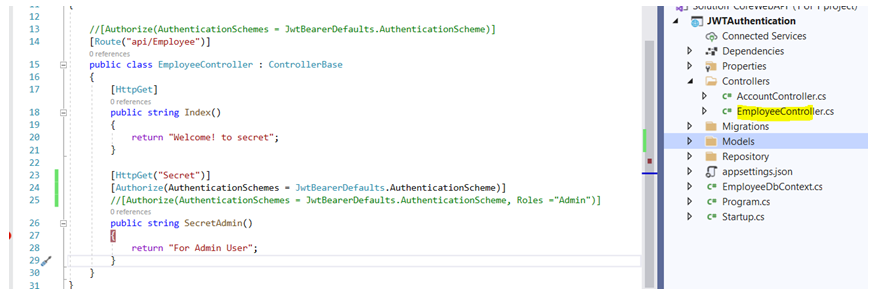
In this article I will show you how to authenticate web api using JWT token. JWT stands for Json Web Token. I have created separate blog to explain about what is JWT and how it work please visit the blog from here. Before proceding this tutorial I will strogly recommend to read previos article to have good understanding on asp.net Core API. Create asp.net core web api project and create Model class shown below.







posted by Asif Sayyad @ May 26, 2021
0 Comments
![]()
#5 Minutes Of Reading In this article, I will show you how to consume web API from console application and asp.net core web application in upcoming article. I’m using web API project created in Part 7 of Web API series and code available here. I have two API method Get and Get with specific Id shown below and consuming below methods in this article.




posted by Asif Sayyad @ May 23, 2021
0 Comments
![]()
#5 minutes of reading In this article I will show you, how you can configure properties like configuring properties in web.config in old asp.net framework. Here in Asp.Net core we don’t have web.config but core support configuring properties from multiple files like AppSetting.Json, Environment variable, User secrete, command line argument and custom file created to store configuration. Will check all different configuration in asp.net core one by one. Let’s start with appsettings.json. I have created web API project shown below and created Configurationcontroller.



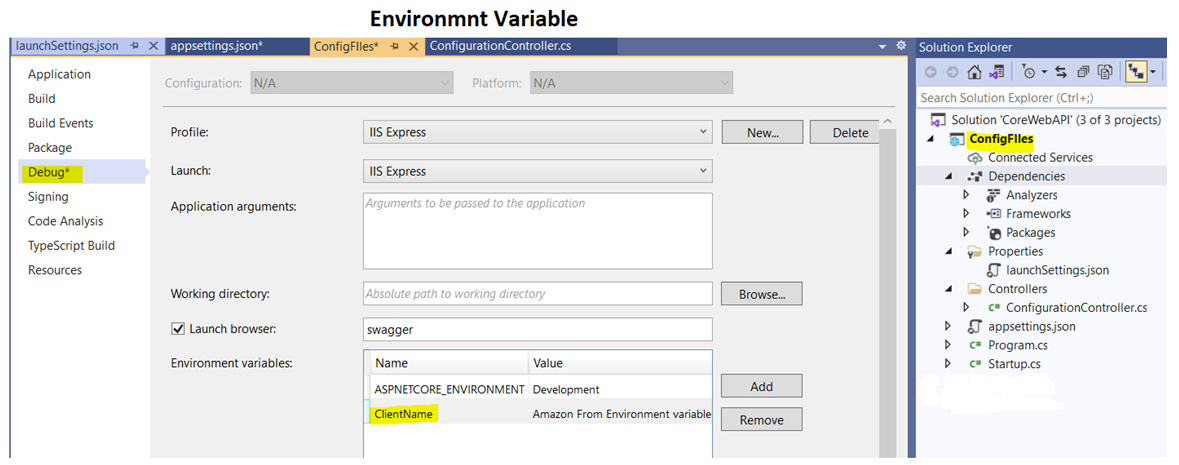






posted by Asif Sayyad @ May 23, 2021
0 Comments
![]()
#5 Minutes Of Reading In this article I will show you how to implement entity framework and how useful dependancy injetcion, I’m moving to database data from in memory data without affecting controller code. This is the advantage of using DI in application. You will came to know as later in this course. Source code available here Change model name from User to Employee shown below.
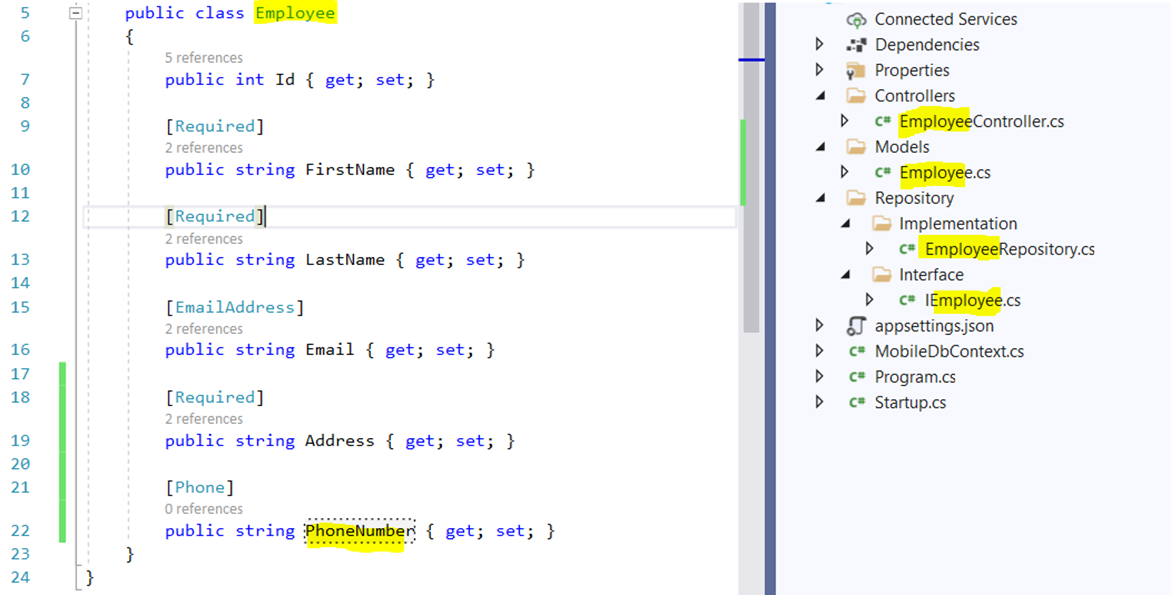




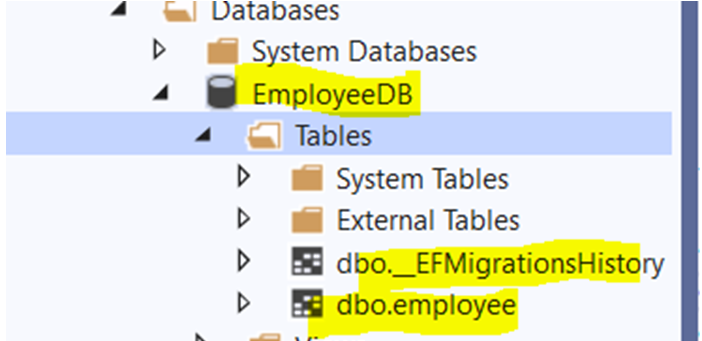





posted by Asif Sayyad @ May 15, 2021
0 Comments
![]()

Subscribe to
Comments [Atom]
