Lets understand disk structure and how table data stores on disk.
In above diagram, orange color section is tracks and yellow color section is sector. In my case based on above diagram, I have disk with 6 sectors and 3 tracks. Track 1 (blue color) is inner circle from above diagram with number 1 shown above which is 2nd inner circle.
Gray color section is block. Block can be identified with the help of sector and track. Above gray highlighted block is from sector 4 and track 2.
Each block from disk has specific memory in my case lets assume 100 byte. Each block in disk is of size 100 bytes. Each block contains 100 offset shown below starts from 0-99.

Now lets understand above concept while storing table data. Suppose, you have database table having 100 rows, and for each 5 rows for storing into disk(Rom) requires 1 block.
Total blocks required to store entire table = 20 blocks
To search any row from this table, It might I have to search entire blocks which is called as table scan or heap. I have to go through and check all 20 blocks where table data stored which is time consuming task.
To avoid this, Index come into picture. Index hold primary key value/index column value as key and base address as value.
Index table also stored on disk and each 25 rows from index takes 1 block to store. Total records from index takes 4 blocks.
Now to find any specific records from table if index available, I need to go through 5 block, 4 blocks from index and 1 block is from actual block where row stored. I can directly find specific row address using index block.
Instead of scanning 20 blocks I have to scan 5 block which reduces time but also increase some space in disk to manage index.
Lets understand this with diagram shown below.

But as size of table increase, index size also increase and needs to search entire index, to avoid this multilevel index come into picture.
For storing database records, B-tree is used. Above diagram is just for understanding how actually multilevel index and DB table are in relation to reduce time reading data from database table.
B tree is extension to M-search tree, which is again created based on above concept of multilevel index. Support I want to retrieve
Lets turn diagram and understand with tree structure.
There are two major type of indexes in MS SQL Server
1. Cluster Index
2. Non Cluster Index
Cluster Index : Clustered index stored table data physically in sorted order. As clustered stored table data physically sorted order only one clustered index can be created per table. By default clustered index get created if primary is created for table. Internally it uses B-tree data structure and leaf node of B-tree contains table data.
Insert, update and delete operation become slow as data stored physically in sorted order. For insert or update operation it check free space available in page or not and if space not available in that case it make space available and insert/update data.
To avoid this, while creating index make sure you provide fill factor. Fill factor is percentage of occupied memory in page. Suppose you provide 80 as fill factor in that case 80% page filled and remaining 20% remains free.
Non Clustered Index : Non Clustered index not sort data physically in table. Non Clustered index can be created more than one and max 999 per table. Non clustered index also follow B-tree to stored data but leaf nodes of B-tree contains reference of page extend which contains table data.
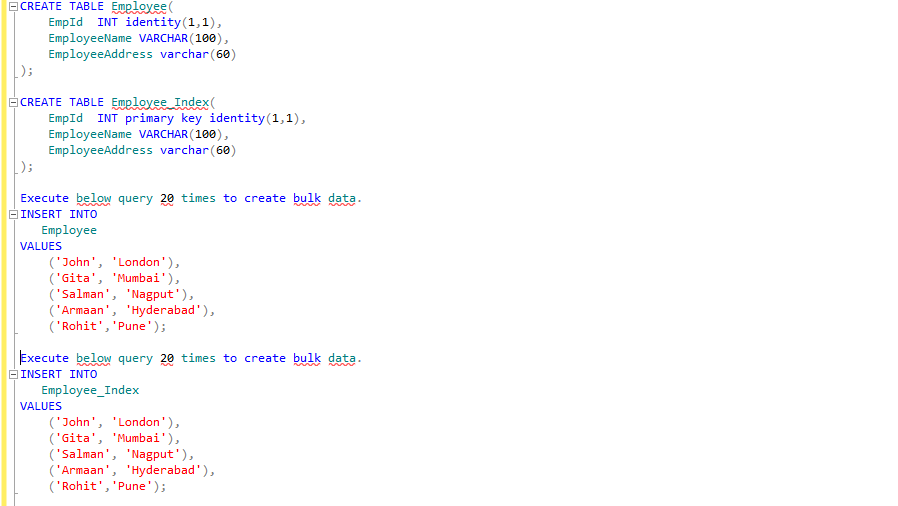
Lets create table with index and without index to compare performance.
Right click on above query and select menu option display estimate execution plan.








0 Comments:
Post a Comment
Subscribe to Post Comments [Atom]
<< Home